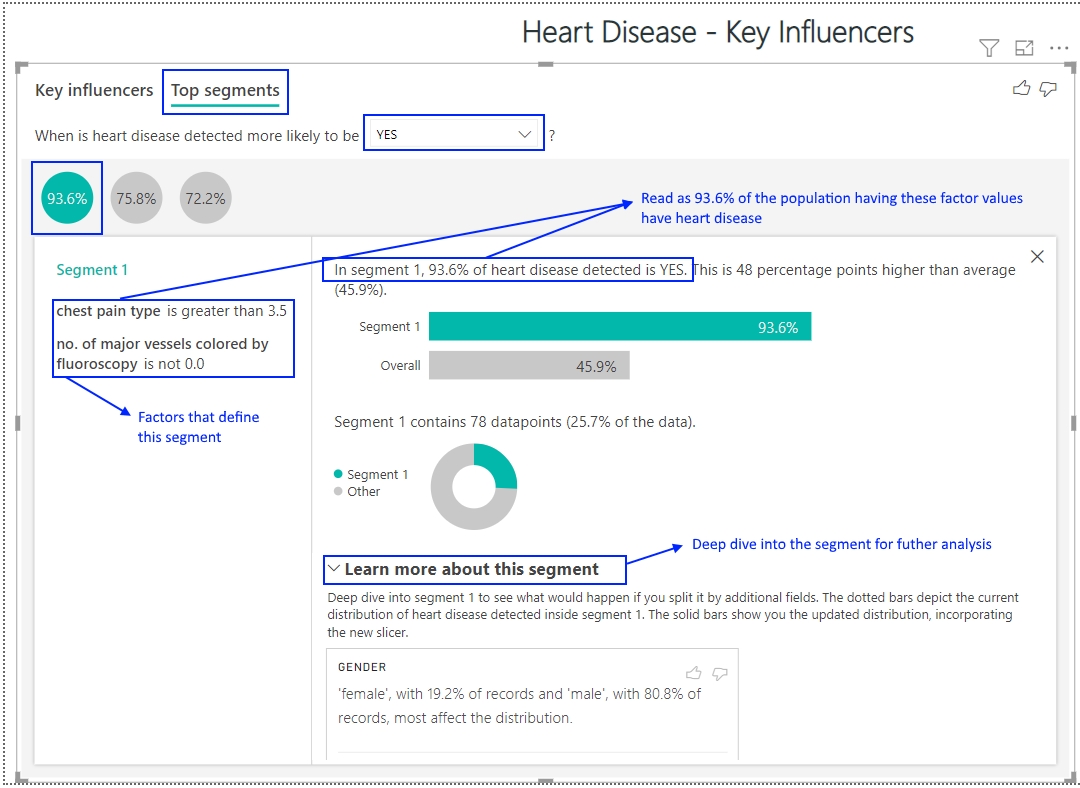
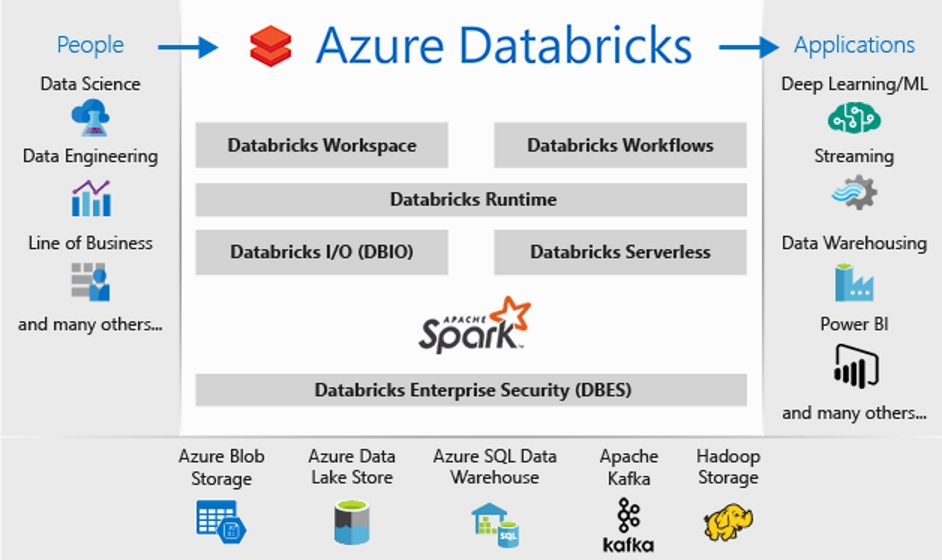
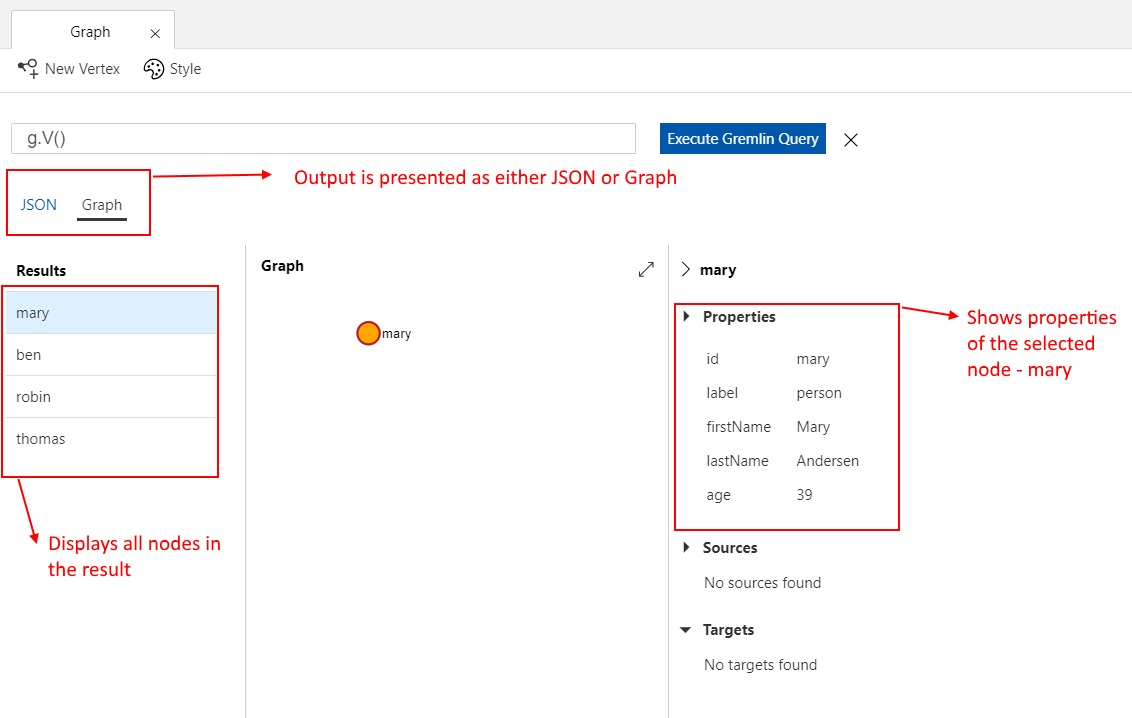
I haven’t done much blogging in the last 6 months. My last article was posted in January, on Data Governance in the Covid era. After changing jobs in March, I prioritized getting settled into my new role. That said, I have had the writer’s itch for a while and thought what better topic to break the rut with than Cosmos DB. I am a big fan of Cosmos DB – Microsoft’s multi-model NoSQL database service in Azure, and I have written a few articles on the topic.
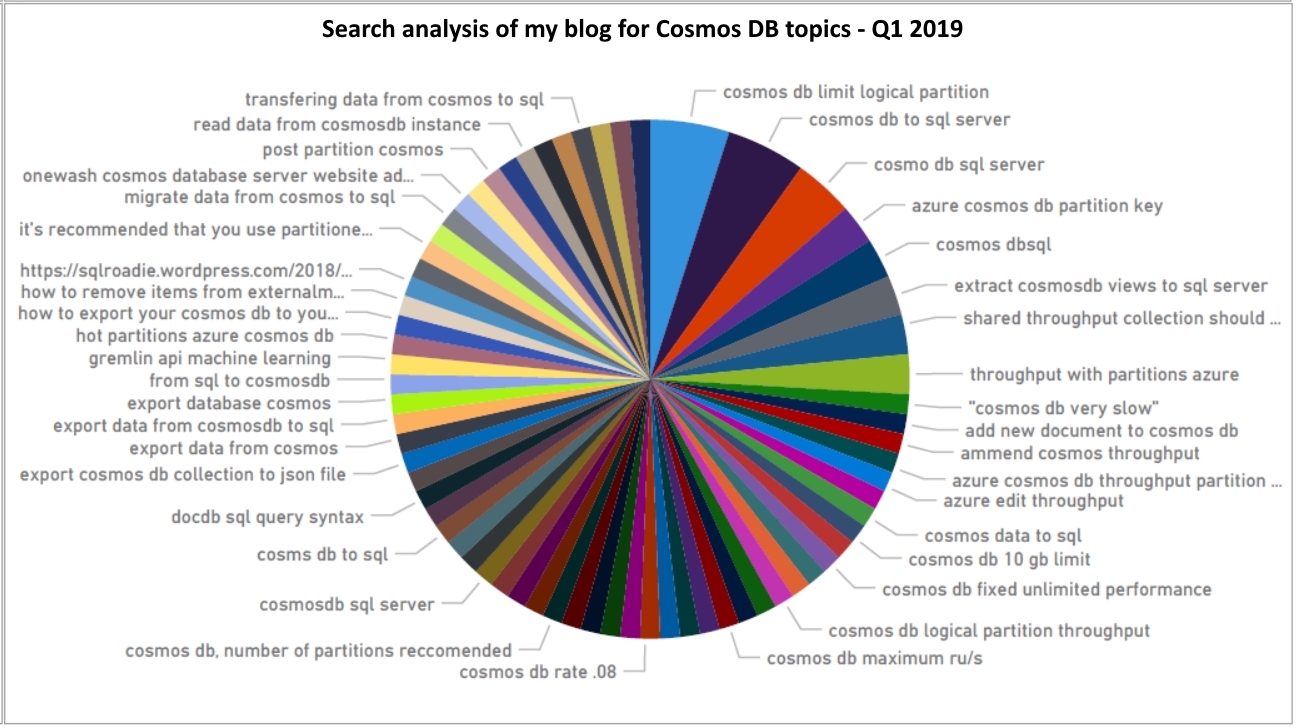
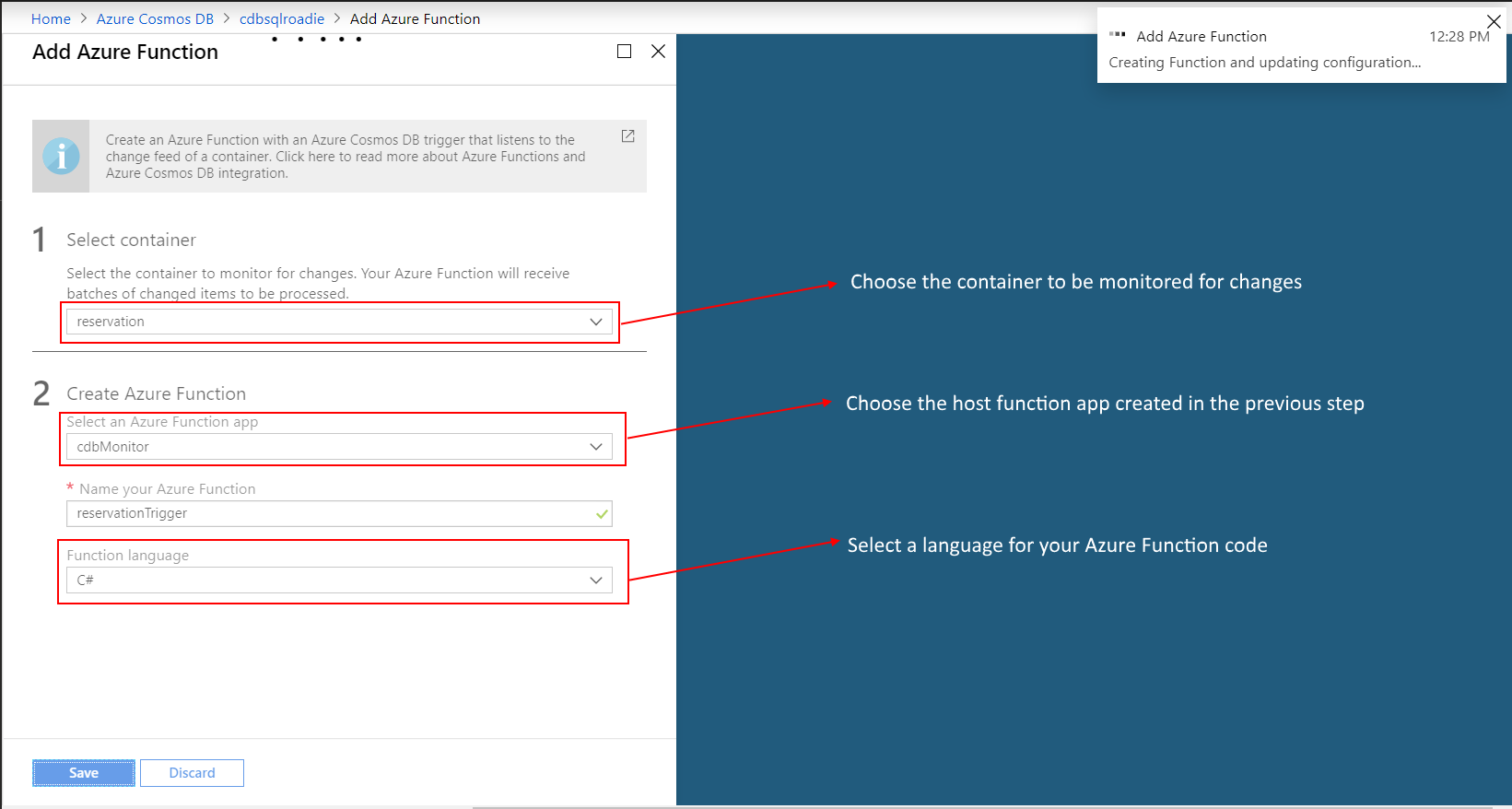
Recent stats of my blog show more interest in data movement out of Cosmos DB, possibly for reporting purposes. Check out my 2019 article on real-time data movement from Cosmos DB using Change Feed and Azure Functions, where I explained how to persist container changes to SQL Server. Well, that is one way to enable real-time analytics. Cosmos DB has evolved a lot since then, and there are new and smarter ways to achieve similar results. Last year (Dec 2020), Microsoft announced the general availability of Azure Synapse Analytics – the unified analytics service in Azure.
HTAP capabilities of Cosmos DB using Synapse Analytics
In this article, we will explore the HTAP capabilities of Cosmos DB. The goal is to derive real-time insights from transactional changes made to Cosmos DB, in a cost-effective manner with minimal overhead. I want the solution to be scalable, reliable and overall simple to maintain.
What is HTAP?
HTAP stands for hybrid transaction/analytical processing. Traditionally, data systems can be classified as either OLTP – Online Transaction Processing or OLAP – Online Analytical Processing. Amazon shopping website is a good example of an OLTP system, as it manages millions of customer orders daily in real-time. However, Amazon would have billions of historical customer order details in their OLAP data warehouse. This helps them to create product recommendations by analyzing historical order data, and serve it to the OLTP system through analytics APIs.
Ordinarily, transaction data has to be copied or replicated from OLTP -> OLAP databases through ETL processes, and reporting/insights/recommendations generated in the OLAP system at a latency that made business sense. This is a tedious process and involves a lot of overhead. Majority of enterprises still use this approach. However, advancements in computing have enabled a new age HTAP architecture.
Gartner defines HTAP as “a hybrid transaction/analytical processing (HTAP) architecture is best enabled by in-memory computing techniques and technologies to enable analytical processing on the same data store that is used to perform transaction processing. By removing the latency associated with moving data from operational databases to data warehouses and data marts for analytical processing, this architecture enables real-time analytics and situation awareness on live transaction data as opposed to after-the-fact analysis on stale data.“
This is exciting stuff, and quite a game-changer in the world of databases. Enough said, how do we go ahead and design a solution using Cosmos DB’s HTAP capabilities!
Synapse Link for Cosmos DB
Synapse Link for Cosmos DB is a cloud-native HTAP capability that creates a tight seamless integration between Cosmos DB and Synapse Analytics. It gives you the ability to gain near real-time analytics and insights over operational data in Cosmos DB with no ETL and no impact to the performance of OLTP transactions in Cosmos DB containers.
Let us break that down. Cloud-native (if you didn’t click the link) is the modern approach, where you design systems using cloud services to scale and perform well consistently. Synapse Analytics (if you are not familiar) can be thought of as Microsoft’s cloud data warehouse, for starts. And that is because Synapse is a lot more than that, but we have to start somewhere, don’t we?
So, Synapse Link creates a seamless, automagic integration between Cosmos DB and Synapse Analytics, thus removing the need for ETL. How does that work? Because a picture is worth a thousand words, I have referred to a diagram from Microsoft’s official doco on Synapse Link. The highlighted portion is new and works behind the scenes to deliver near-real time analytics with no additional ETL. When we create a container in an Azure Cosmos DB account that has Synapse Link enabled, an analytical store is automatically provisioned. This analytical store helps to ensure that there is no impact to OLTP transactions against the Cosmos DB container.

This is a robust mechanism to perform large-scale analytics over data in Cosmos DB and implement an archival policy efficiently to keep the containers sleek without losing access to valuable historical data. It is worth noting that the transactional and analytical stores get their own, separate TTL (Time to Live) properties. TTL is one of my favorite features of Cosmos DB. Self-destruction can be so powerful sometimes! I will cover this in more detail in my sample solution.
Sample Solution
Confucius says, “I hear and I forget. I see and I remember. I do and I understand”. So, I built a sample solution that would ingest data into Cosmos DB at scale, and I was impressed at just how quickly data was available downstream in Synapse Analytics. The sample solution features a Python Notebook, running on Databricks and ingesting the popular New York City taxi trip data into a Cosmos DB container using Cosmos DB Spark 3 OLTP connector for SQL API. The trip data that became available in Synapse Analytics was used to build a Power BI dashboard, thus effectively producing near real-time analytics with no ETL and minimal code. I will give a step-by-step breakdown of the sample solution. Refer to this guide by Microsoft for more details.

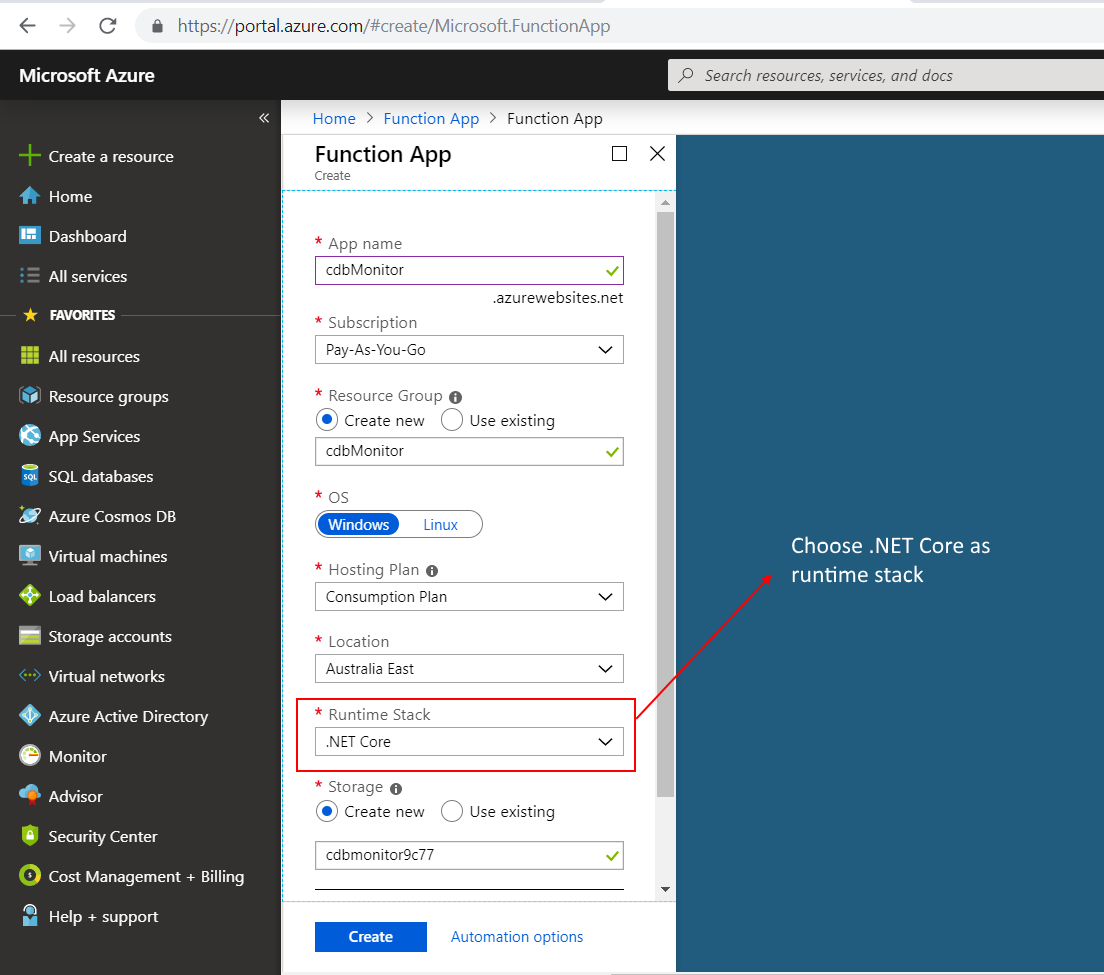
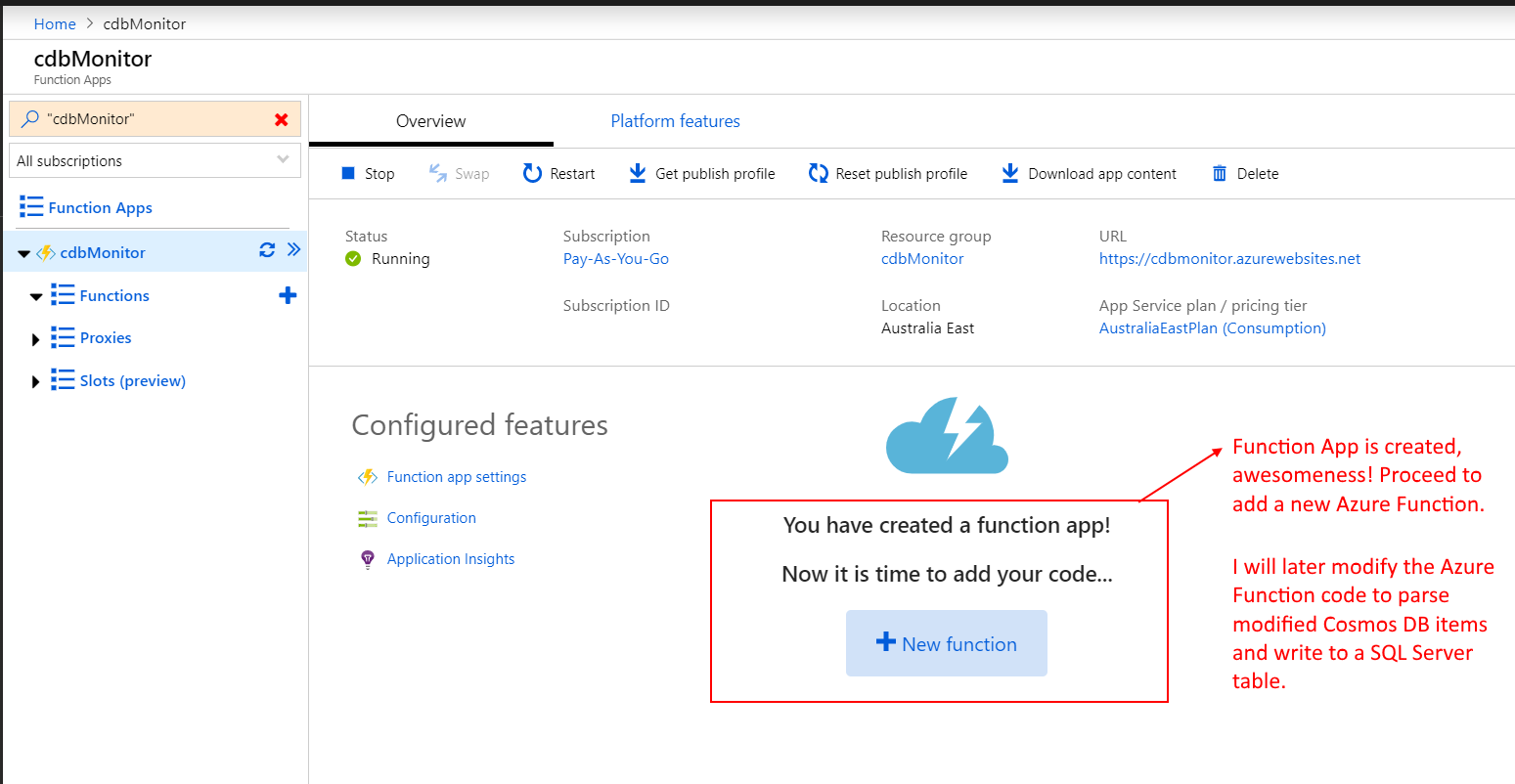
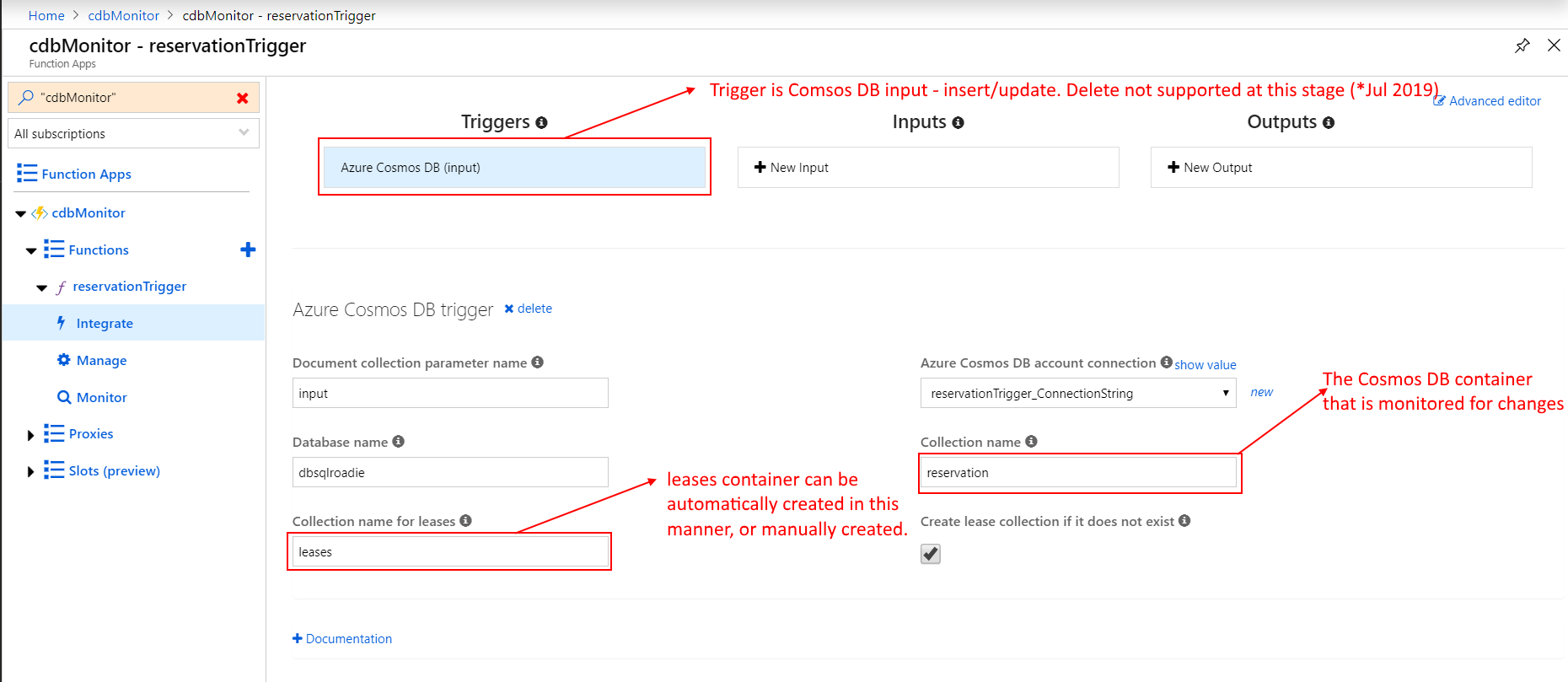
1. Cosmos DB container
Firstly, we want to enable Synapse Link in the Cosmos DB account using the Settings blade. It is worth noting that at the time of writing this article (Oct 2021), Synapse Link and analytical store is supported only for SQL and MongoDB APIs.
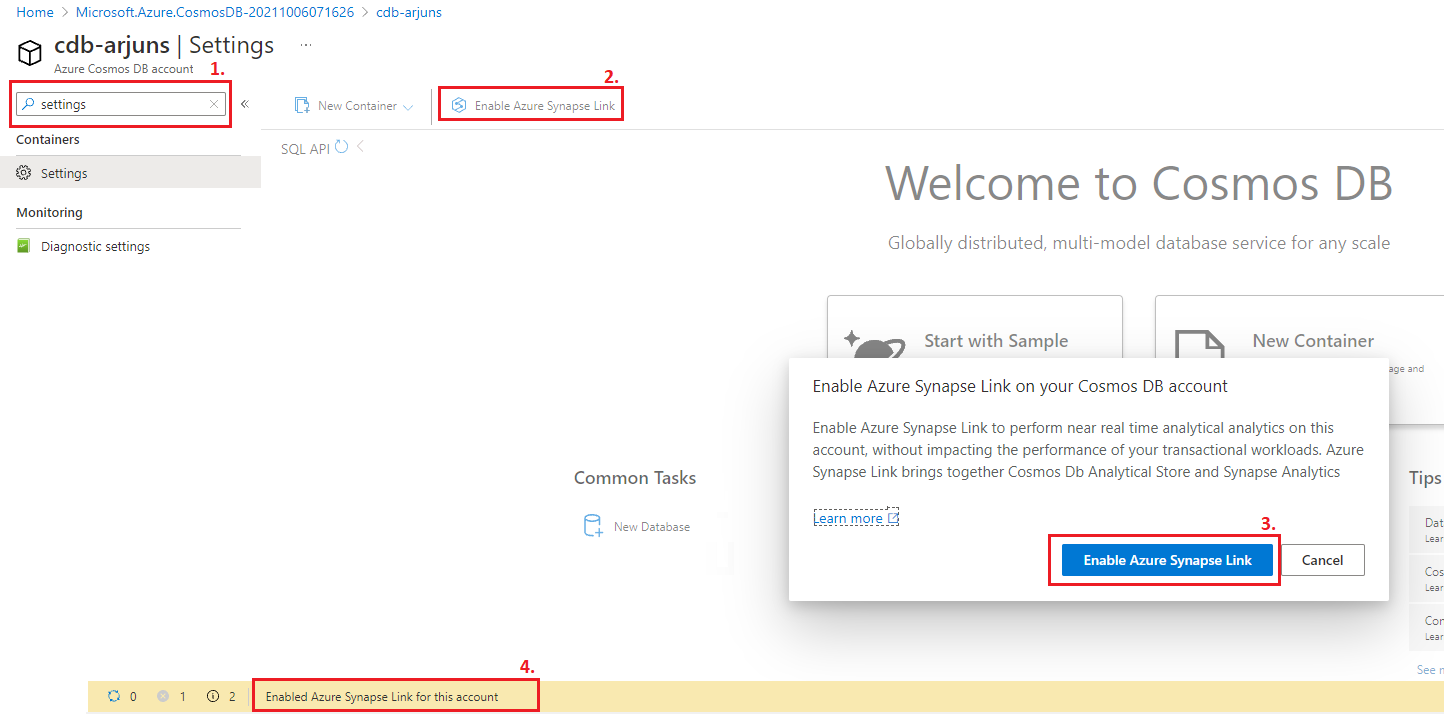
At the moment, analytical store can be turned ON only for new containers. If you wish to make use of Cosmos DB’s HTAP capabilities for an existing container, you will need to migrate data to a new container. Note that containers cannot be renamed. Auto-sync latency is within 2 minutes, as per Microsoft documentation. In my tests, I did not see a delay of more than a minute or so for data to be available downstream in Synapse Analytics.
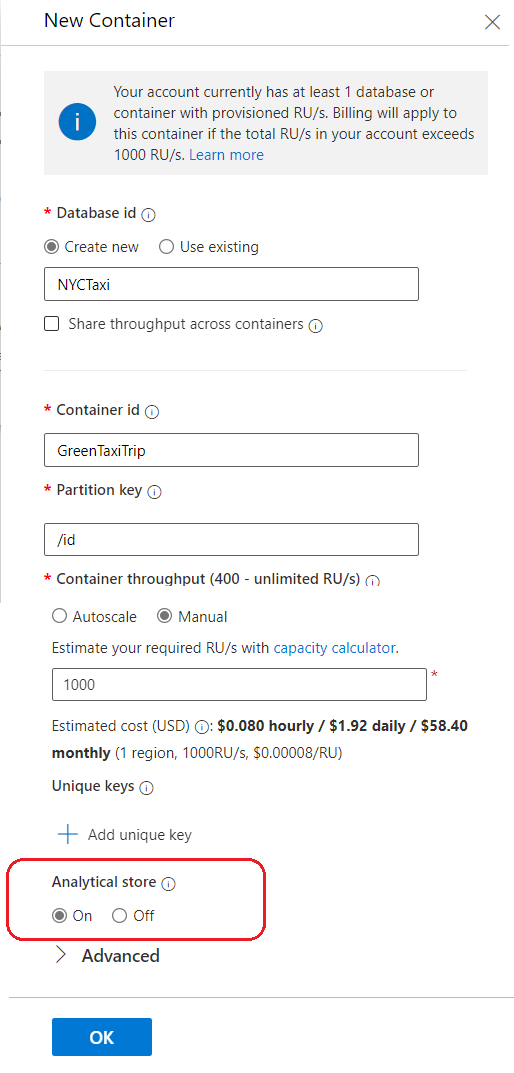
Analytical store does not need request units (RU/throughput) to be allocated, nor does it consume the RU assigned to the transactional store – 1000 in the snip above. Analytical store follows a consumption-based pricing model, which is based on data storage and analytical read/write operations and queries executed. Storage can be optimized by setting the Analytical Store Time To Live property in the Data Explorer blade under Scale & Settings option. This dictates for how long data would be retained in the analytical store, and is independent from the container TTL property. You should set the Analytical Store TTL to a value that gives you sufficient time to process the data and persist or derive insights from it as required. At the time of writing this article (Oct 2021), analytical store does not support backup and restore, i.e. if a Cosmos DB backup is restored, only the transactional store will be recovered. It is also worth noting that schema representation in the analytical store could be different from the container schema.
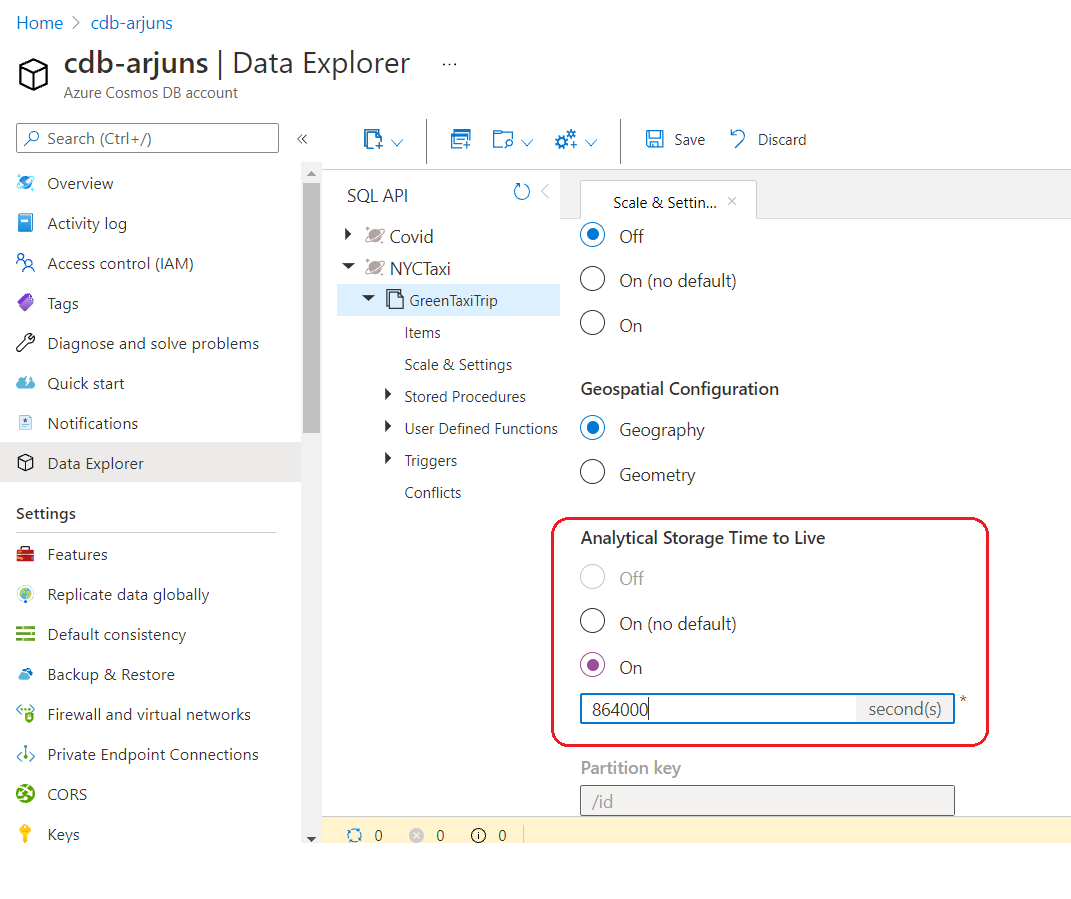
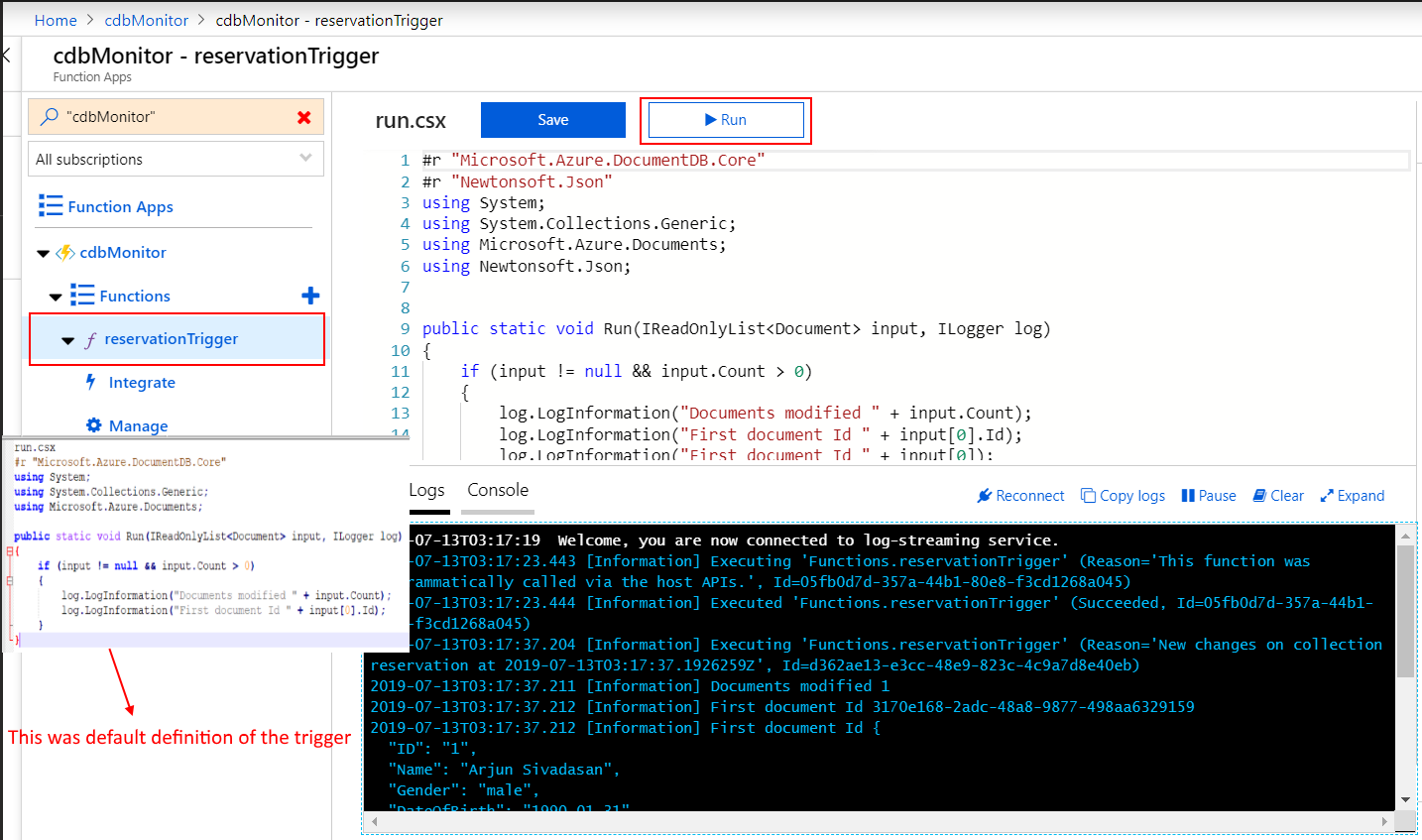
2. Databricks – Python notebook to write NYC Taxi trip data to Cosmos DB
In the sample solution, I used a Python notebook to write data to Cosmos DB using the Spark 3 OLTP Connector for SQL API. This was just to simulate incoming OLTP application requests.



3. Synapse Analytics
In the Synapse Workspace, Cosmos DB analytical store may be accessed using the Spark pool or built-in serverless SQL pool. I used the serverless SQL pool, which is a pay per query distributed data processing system built for big data and computational functions.

In the Synapse Studio, I created a linked service by connecting to the external Cosmos DB resource.

In this case, I chose Managed Identity as the authentication method.

In a little while, the linked service was added. At this stage, we are almost ready to query the underlying analytical store of GreenTaxiTrip container.

The next step was to create a user database in the serverless SQL pool, so that a CREDENTIAL could be created to access the Cosmos DB database securely. You cannot create the credential in master database.

4. Data Ingestion
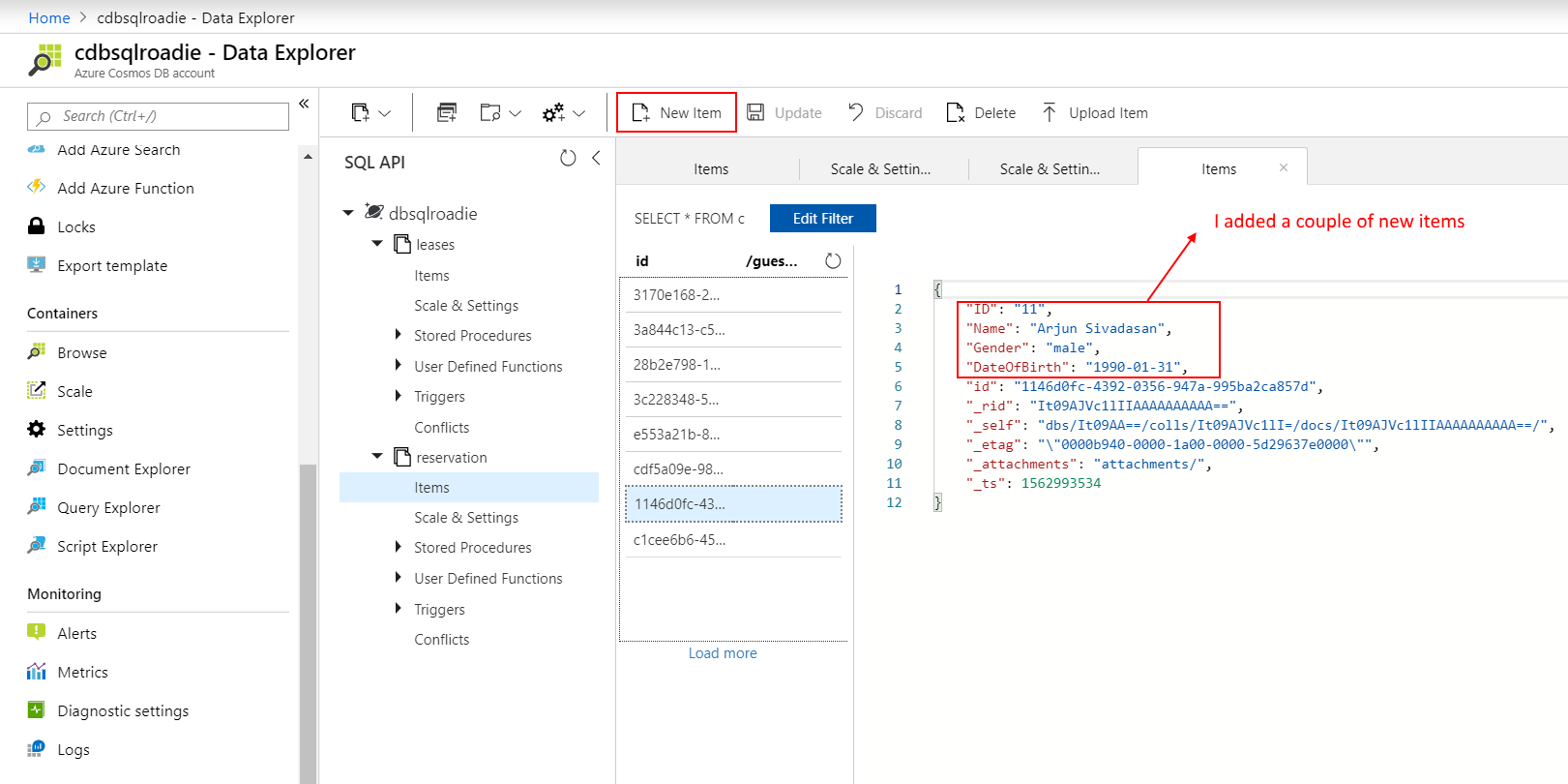
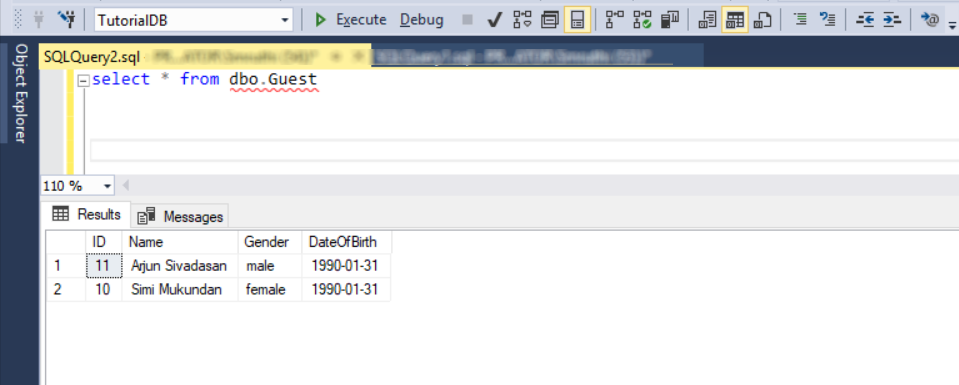
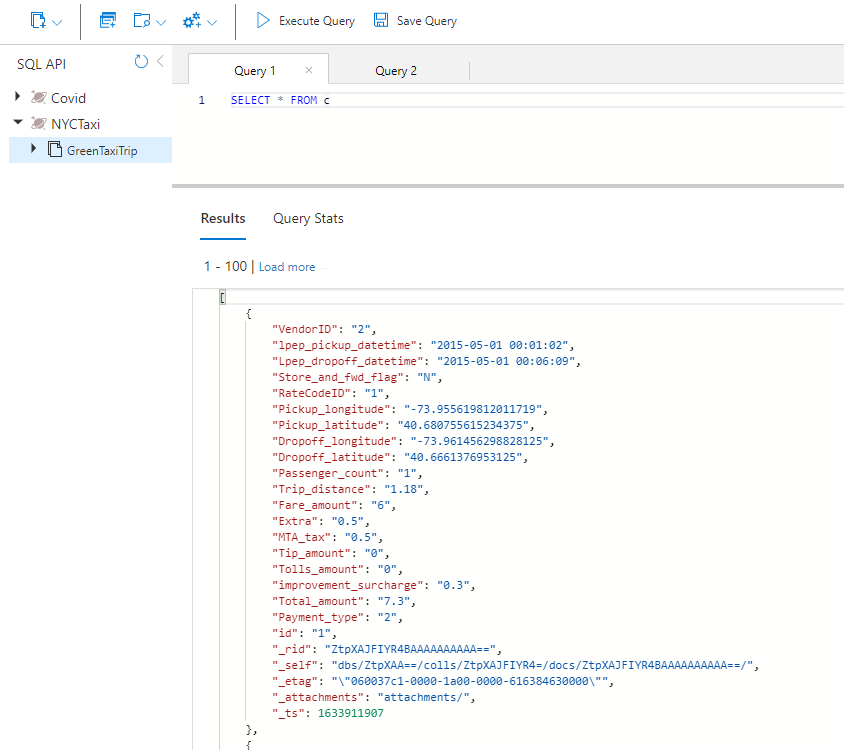
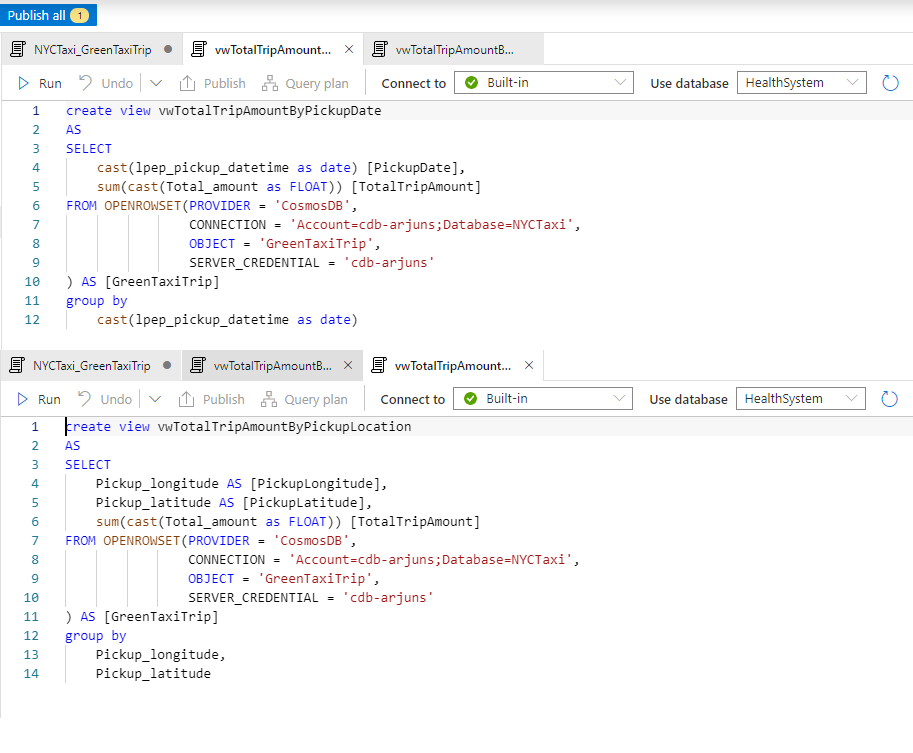
I scheduled a Databricks job to execute the Python notebook to ingest NYC Taxi trip data from DBFS to Cosmos DB using the Spark 3 OLTP connector for SQL API. You may also execute it manually. Once data became available in Synapse Analytics through the analytical store, I wrote a couple of queries over the data using familiar T-SQL and converted them to views.

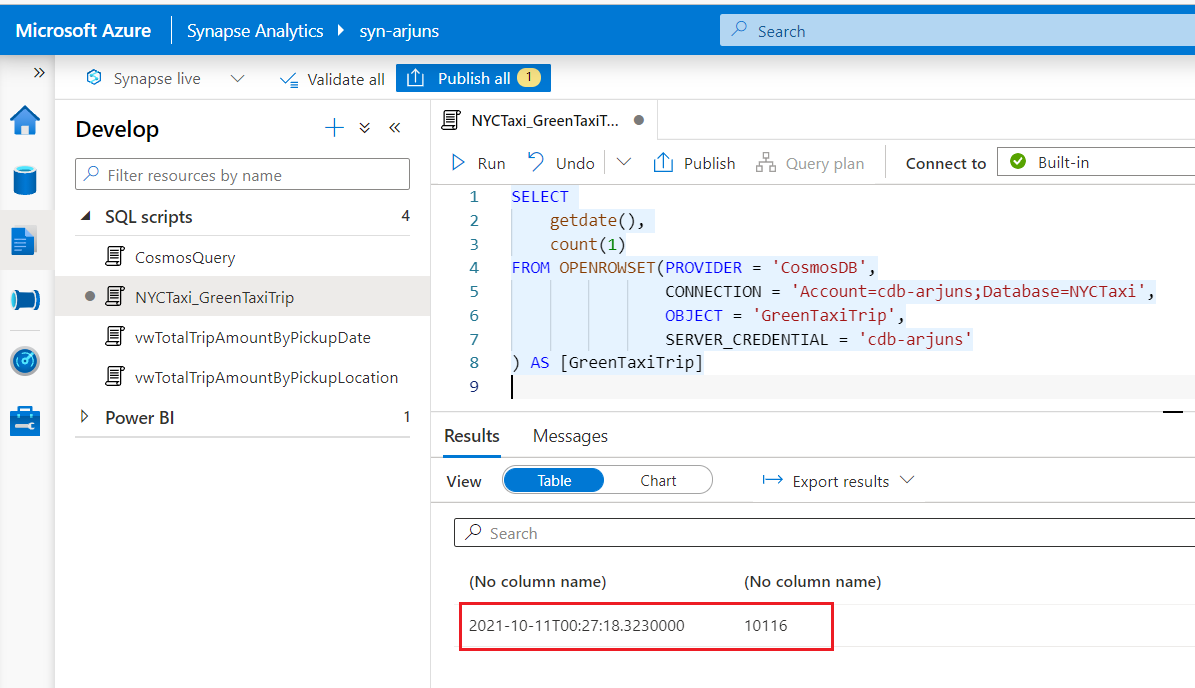
Note the number of records, and the corresponding timestamp in the transactional store. When the record count query completed in Synapse Analytics 9 seconds later, the number of records were out by only 545! Auto-sync latency is 2 minutes, as per Microsoft doco. It is worth noting that even if a document had a TTL set to lower than 2 minutes, it would still appear in the analytical store however, I have not tested it.

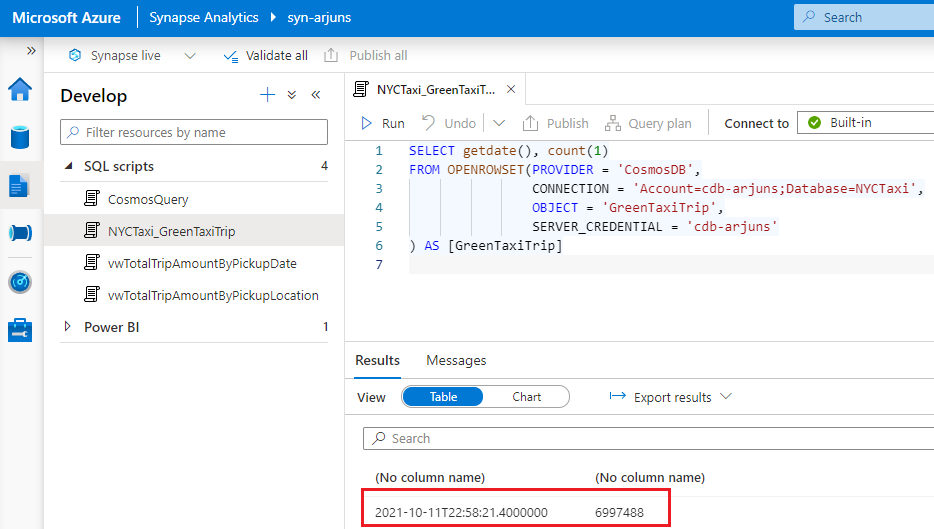
My test dataset had 7 million records, and I left the job running to see how well the analytical store would perform. I was quite satisfied with the performance of Synapse Link. In this case, I used only one container but it would be interesting to see how well auto-sync holds up at scale.

5. Near real-time analytics using Power BI
Having validated that trip data written to the Cosmos DB container were visible in Synapse Analytics in near real-time, I proceeded to create 2 simple views using the OPENROWSET function, and a Power BI dashboard that used the views as its data source. Please excuse my lazy visualization efforts, but the point is you can easily get near real-time insights over operational data at scale using Synapse Link. All without any ETL!

Other alternatives
When it comes to enabling analytics over operational data in Cosmos DB, I cannot think of a better way to do it. The Change Feed way of doing it is not as scalable or easily maintainable as using Synapse Link. The obvious difference is that you will need a Synapse Analytics account to make use of Synapse Link. If you are a Microsoft house, this would make sense as Synapse is the unified analytics service and integrates directly with several services such as Azure Machine Learning, Cognitive Services and Power BI.
Limitations
At the time of writing this article (Oct 2021), Synapse Link for Cosmos DB is only supported for the SQL and Mongo DB APIs. I think it will be really cool to have it enabled for the Gremlin API. Graph databases are getting increasingly popular, and graph-enabled analytics such as fraud detection and money laundering is bound to become more common place.
More limitations are available here. The most glaring one is the lack of support for backup and restore of data in the analytical store.
The road ahead
HTAP is made possible by the power of cloud computing. I believe it will not be too long before HTAP capability is available for Azure SQL databases. That will be quite a game changer!
Aside from the basic Business Intelligence feature I demonstrated in the sample solution, Synapse Analytics also enables batch scoring using native scoring for models trained using RevoscalePy and RevoscaleR packages, AutoML to develop a Regression/Classification/Time Series Forecasting model using the Azure Machine Learning linked service, and multi language support for advanced analytics using the Spark pool.
Cosmos DB’s HTAP capability is fascinating, and I can think of several use cases to enable real-time decision intelligence at scale. I hope you had a good read. Please leave a comment if you have questions or any feedback.
References
https://docs.microsoft.com/en-us/azure/cosmos-db/synapse-link
https://docs.microsoft.com/en-us/azure/cosmos-db/analytical-store-introduction
https://docs.microsoft.com/en-us/azure/cosmos-db/configure-synapse-link
https://www.youtube.com/watch?v=H6Ei_t34BGs – Jovan Popovic
https://www.youtube.com/watch?v=yd8vynwA36A – Microsoft Mechanics
https://devblogs.microsoft.com/cosmosdb/spark-3-connector-databricks/
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/create-sql-api-spark
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/sql-api-sdk-java-spark-v3
https://github.com/Azure/azure-sdk-for-java/blob/main/sdk/cosmos/azure-cosmos-spark_3-1_2-12/docs/configuration-reference.md#write-config
https://docs.microsoft.com/en-us/sql/relational-databases/security/authentication-access/credentials-database-engine?view=sql-server-ver15
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-openrowset
https://docs.microsoft.com/en-us/azure/synapse-analytics/machine-learning/tutorial-automl