Many people who read my Cosmos DB articles are looking for an effective way to export data to SQL, either on-demand or in real-time. After performing a search term analysis for my blog earlier this year, I had made up my mind about posting a solid article on exporting data from Cosmos DB to SQL Server.
Note that this serverless and event-based architecture may be used to not only persist Cosmos DB changes to SQL Server, but trigger alternate actions such as stream processing or loading to blob/Data Lake.

Real-time ETL using Cosmos DB Change Feed and Azure Functions
In this article, we will focus on creating a data pipeline to ETL (Extract, Transform and Load) Cosmos DB container changes to a SQL Server database. My main requirements or design considerations are:
- Fault-tolerant and near real-time processing
- Incur minimum additional cost
- Simple to implement and maintain
Cosmos DB Change Feed
Cosmos DB Change Feed listens to Cosmos DB containers for changes and outputs the list of items that were changed in the chronological order of their modification. Cosmos DB Change Feed enables building efficient and scalable solutions for the following use cases:
- Triggering a notification or calling an API
- Real-time stream processing
- Downstream data movement or archiving

Types of operations
- Change feed tracks inserts and updates. Deletes are not tracked yet
- Cannot control change feed to track only one kind of operation, for example only inserts
- For tracking deletes in the Change Feed, workaround is to soft-delete and assign a small TTL (Time To Live) value of “n” to automatically delete the item after “n” seconds
- Change Feed can be read for historic items, as long as the items have not been deleted
- Change Feed items are available in order of their modification time (_ts system attribute), per logical partition key, and tagged with the same _lsn (system attribute) value for all items modified in the same transaction
Read more about Azure Cosmos DB Change Feed from Microsoft docs to gain a thorough understanding. Change Feed can be processed using Azure Functions or Change Feed Processor Library. In this article, we will use Azure Functions.
Azure Functions
Azure Functions is an event-driven, serverless compute platform for easily running small pieces of code in Azure. Key points to note are:
- Write specific code for a problem without worrying about an application or the infrastructure to run it
- Use either C#, F#, Node.js, Java, or PHP for coding
- Pay only for the time your code runs and trust Azure to scale
- As of July 2019, the Azure Functions trigger for Cosmos DB is supported for use with the Core (SQL) API only
Read more from Microsoft docs to understand full capabilities of Azure Functions.
If you use Consumption plan pricing, it includes a monthly free grant of 1 million requests and 400,000 GBs of resource consumption per month per subscription in pay-as-you-go pricing across all function apps in that subscription, as per MS docs.
Compare hosting plans and check out pricing details for Azure Functions at the Functions pricing page to gain a thorough understanding of pricing options.
Real-time data movement using Change Feed and Azure Functions
The following architecture will allow us to listen to a Cosmos DB container for inserts and updates, and copy changes to a SQL Server Table. Note that Change Feed is enabled by default for all Cosmos DB containers.
I will create a Cosmos DB container and add an Azure Function to listen to the Cosmos DB container. I will then modify the Azure Function code to parse modified container items and save them to a SQL Server table.
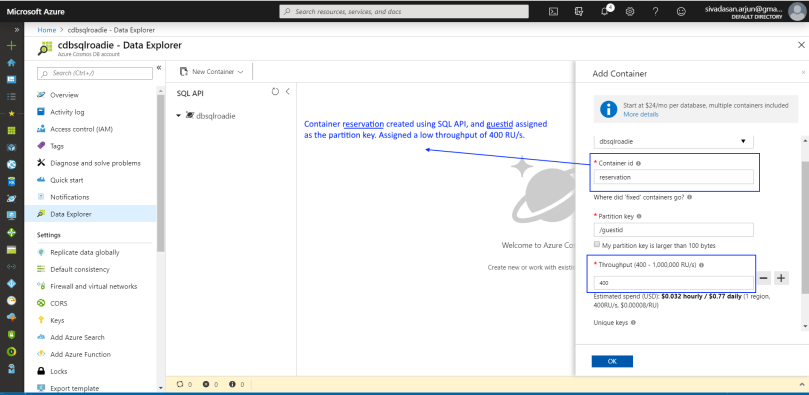
1. First, I navigated to Azure portal, Cosmos DB blade and created a container called reservation in my Cosmos DB database. As it is purely for the purposes of this demo, I assigned lowest throughput of 400 RU/s

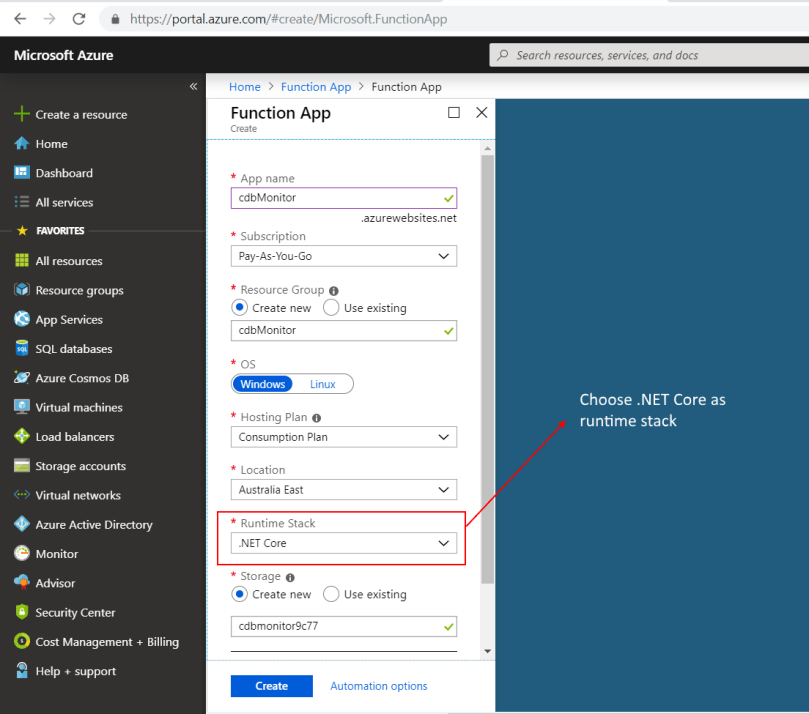
2. Now that the container is ready, proceed to create an Azure Function App. The Azure Function will be hosted in the Azure Function app

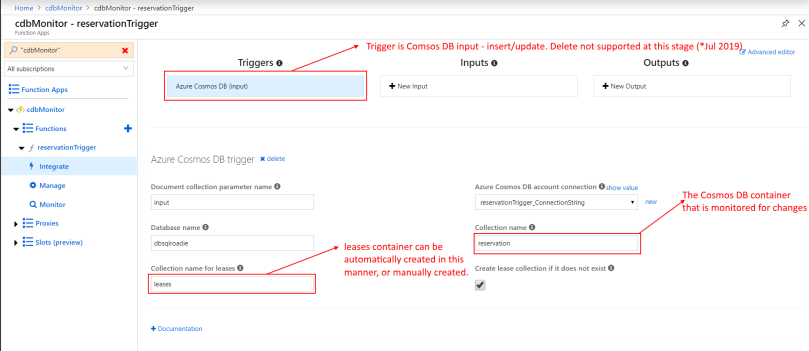
3. Add an Azure Function within the newly created Azure Function App. Azure Function trigger for Cosmos DB utilizes the scaling and event-detection functionalities of Change Feed processor, to allow creation of small reactive Azure Functions that will be triggered on each new input to the Cosmos DB container.



4. Configure the trigger. Leases container may be manually created. Alternately, check the box that says “Create lease collection if it does not exist”. Please note that you would incur cost for storage and compute for leases container.
I got this error that read – “The binding type(s) ‘cosmosDBTrigger’ are not registered. You just need to install the relevant extension. I saw many posts about this, so it will most likely be fixed soon.

Sort out the error by installing the extension for Azure Cosmos DB trigger.

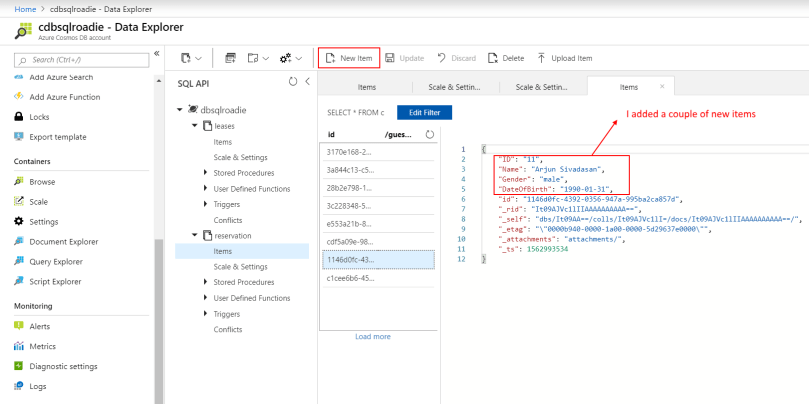
5. Once the function is up and running, add an item to the reservations container that we are monitoring. And we have a working solution!

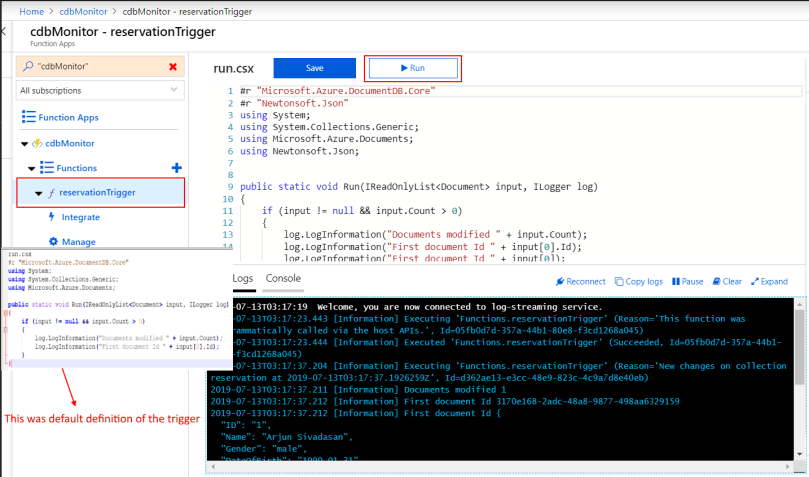
6. Trigger definition may be modified to achieve different things, in our case we will parse the feed output and persist changes to SQL server. You can download the csx file I used.



Summary
We have successfully implemented a serverless, event-based low cost architecture that is built to scale. Bear in mind that you would still end up paying for Azure Function and the underlying leases collection, but there will be minimum additional RU cost incurred from reading your monitored container(s) as you are tapping into the Change Feed.
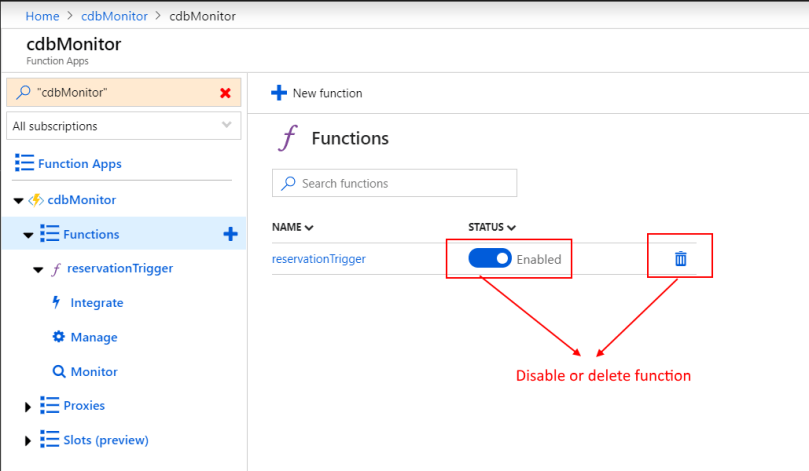
You can monitor the function and troubleshoot errors.

I hope you found the article useful. Add a comment if you have feedback for me. If you have any question, drop me a line on LinkedIn. I’ll be happy to help 🙂 Happy coding!
Resources:
https://docs.microsoft.com/en-us/azure/cosmos-db/change-feed
https://docs.microsoft.com/en-us/azure/cosmos-db/changefeed-ecommerce-solution
https://azure.microsoft.com/en-au/services/functions/
https://docs.microsoft.com/en-us/azure/azure-functions/functions-overview
https://docs.microsoft.com/en-us/azure/azure-functions/functions-bindings-cosmosdb-v2
https://docs.microsoft.com/en-us/azure/cosmos-db/change-feed-functions
https://azure.microsoft.com/en-au/resources/videos/azure-cosmosdb-change-feed/
https://h-savran.blogspot.com/2019/03/introduction-to-change-feed-in-cosmos.html
















 3. Time to Live: TTL can be set at a collection or document level. Document level TTL takes precedence, obviously.
3. Time to Live: TTL can be set at a collection or document level. Document level TTL takes precedence, obviously.